本文旨在深入探討 ArangoDB - 一款原生多模型資料庫,並分析其在金融服務業的戰略價值。
ArangoDB 能夠無縫整合圖形、文件與鍵值等資料模型,透過統一的查詢語言 AQL 提供一致且高效的資料存取體驗。這使其在處理如詐欺偵測、風險控管、客戶個人化服務等高度互連資料場景中,展現出獨特優勢。
同時,本文亦將透過與 Neo4j 的技術比較,剖析 ArangoDB 在多功能性與效能層面的競爭力,並說明其作為現代金融資料基礎設施的潛力與定位。
圖形資料庫的戰略必要性:釋放互聯數據的洞察力
理解圖形資料庫:核心概念與架構
一、圖形資料庫代表了傳統資料儲存範式的根本性轉變:
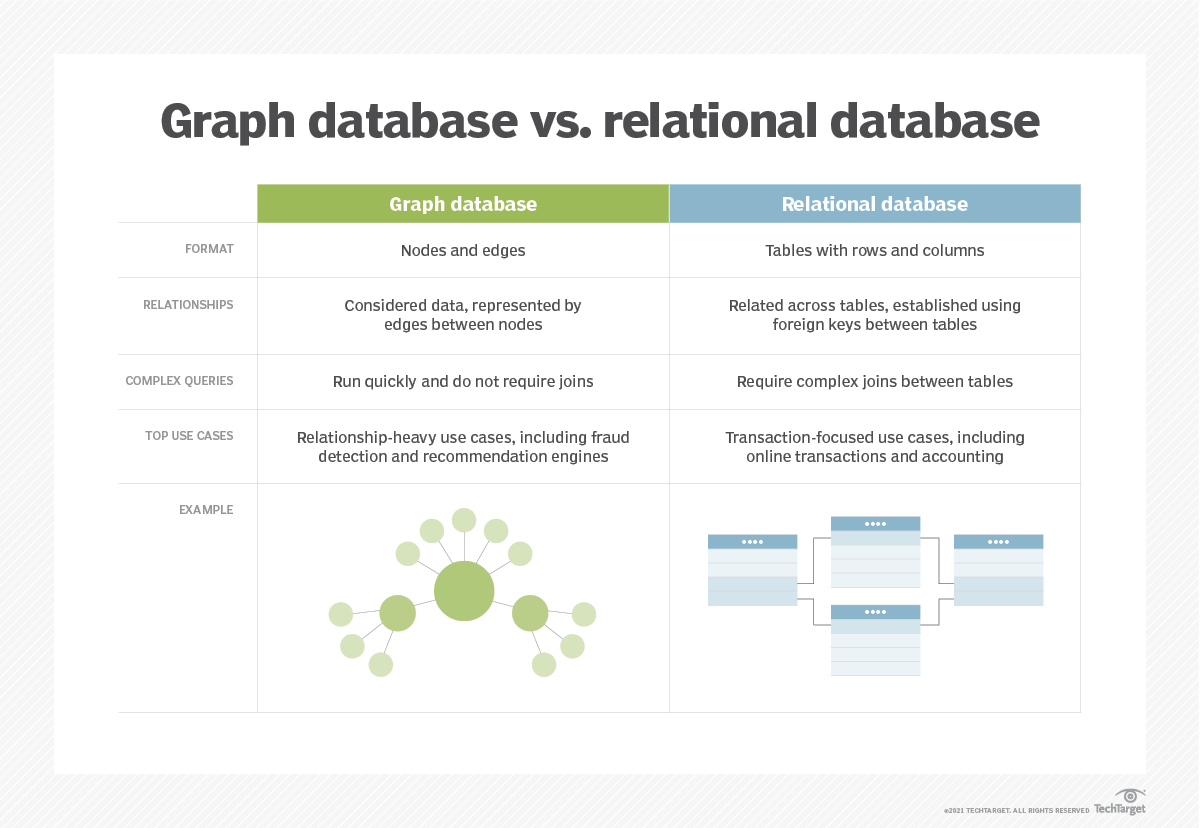
它們是一種系統性的資料集合,其核心在於強調不同資料實體之間的關係。與傳統關聯式資料庫將資料儲存在僵化、預定義的表格中不同,圖形資料庫將資訊建模為互連實體及其關係的網路。這種以 Node/Edge 為中心的方法是其決定性的特徵。
二、圖形資料庫中的資料架構圍繞兩個主要組成部分:
- 節點 (Nodes): 這些代表實體,例如客戶、金融交易、銀行帳戶或設備。節點可以擁有描述它們的屬性(例如,客戶節點可能具有 姓名、地址、帳戶狀態 等屬性)。
- 邊 (Edges) 或關係 (Relationships): 這些代表節點之間的連接或互動。邊總是具有方向性,指示關係的性質(例如,「客戶 A 與 帳戶 B 交易」、「設備 X 由 客戶 Y 使用」)。與節點一樣,邊也可以擁有描述關係本身的屬性(例如,「交易」邊可能具有 交易金額、時間戳、地點 等屬性)。這種直接的關係表示方式有助於高效地遍歷和查詢複雜的連接。
圖形資料庫的關鍵優勢:靈活性、效能與關係遍歷效率
圖形資料庫在處理「高度互連資料」時,展現出相較傳統關聯式資料庫更明顯的優勢,尤其在現代金融、社群或推薦系統的場景中格外關鍵。以下是三大重點:
一、靈活性 (Schema Flexibility)
- 相較於傳統資料庫需先定義結構 (Schema),圖形資料庫提供了高度模式彈性。
- 資料分析師可以動態新增或修改節點、邊、屬性,無需影響現有功能或重構整個資料模型。
- 這種「無模式 / 模式靈活」的設計,特別適合需求變化頻繁的資料環境,如即時風險監控或快速產品迭代。
二、效能 (Performance)
- 在處理大量且複雜的關聯資料時,圖形資料庫效能高出數個數量級。
- 清關聯式資料庫在做多層 JOIN 查詢時容易遇到效能瓶頸,而圖形資料庫中的邊(關係)是資料的一等公民,已預先儲存,不需動態計算。單
- 即使資料量劇增,遍歷效能仍能保持穩定。
三、查詢效率 (Query Efficiency)
- 查詢語法更加簡潔直觀,無需像 SQL 那樣層層巢狀 JOIN。
- 利用圖形遍歷 (Traversal),可快速找出節點間的多跳關係與深層模式。
- 產生互連資料的洞察與報告時,不僅執行快,也節省大量資源。
| 優勢 | 描述 | 相關應用場景 |
|---|---|---|
| 靈活性 | 效能 | 效率 |
| 模式可隨應用程式演變而調整;無需預先建模整個領域。 | 關係查詢速度快數個數量級;資料量增加時效能仍保持不變。 | 查詢更簡潔高效;關係直接持久化,無需在查詢時計算。 |
| 敏捷開發、不斷變化的業務需求 | 即時分析、高吞吐量應用 | 複雜報告、資源最佳化 |
圖形資料庫特別適合以下應用場景:
- 社交網路分析:找出社群中的關鍵人物、分析使用者行為模式。
- 推薦系統:根據使用者偏好和商品關聯性提供精準推薦。
- 詐欺偵測:識別異常交易模式和關聯網路,揪出詐欺行為。
- 知識圖譜:構建實體與概念之間的複雜關聯,實現智慧問答和語義搜索。
擁抱資料多樣性:多模型圖形資料庫的力量
定義多模型資料庫:
當我們說 ArangoDB 是「多模態(multi-model)」資料庫時,指的是它能夠在單一資料庫引擎中同 時支援多種不同的資料模型,這讓開發者能根據實際需求選擇最適合的資料表示方式,而不需要 引入多個資料庫系統來分別處理不同類型的資料。
三種主要資料模型:
一、文件模型 (Document Model)
- ArangoDB 支援類似 MongoDB 的文件導向資料模型,資料以 JSON(實際上是 BSON-like 的格 式)文件儲存,這非常適合儲存非結構化或半結構化的資料。例如一個使用者的資料可能就是一 整個 JSON 文件,不需要預先定義 schema。
二、圖形模型 (Graph Model)
- 它也內建支援圖形資料模型(如同 Neo4j),這對於社交網路、推薦系統、網路關係分析等應用非 常實用。節點(vertex)和邊(edge)都本質上是文件,但有圖的語意,加上內建圖查詢語言(比如 AQL 中的 GRAPH 函數),可以輕鬆執行圖遍歷、社交關係深度查詢等操作。
三、鍵值模型 (Key/Value Model)
- 雖然不是傳統的關聯式資料庫,但 ArangoDB 提供可以模擬類似關聯查詢的功能,主要是透過 AQL(Arango Query Language),這是一種類似 SQL 的查詢語言,支援 JOIN、FILTER、SORT 等 操作,讓你能像使用關聯式資料庫一樣操作資料。
ArangoDB 的多模型架構:
ArangoDB 並不是單純把多種模型拼裝在一起,而是在一個核心資料引擎中原生整合了以下模型:
- 形模型 (Graph)
- 文件模型 (Document)
- 鍵值模型 (Key-Value)
- 全文搜尋 (Full-Text Search)
這樣的設計意味著:使用者不必切換資料庫或轉換格式,就能在同一筆查詢中同時操作不同模型的資料。
一、單一查詢語言:AQL
- ArangoDB 採用統一的查詢語言 AQL (Arango Query Language)。
- 它雖然語法與 SQL 不完全相同,但設計目的雷同:讀取、過濾、修改與聚合資料。
- AQL 可同時查詢文件、圖形、關聯等結構,讓工程師在處理多模型資料時,不需學多種語法或整合不同資料庫。
二、原生圖形連接能力
- ArangoDB 的底層架構是以圖形為基礎設計,這讓它在多模型中能自然建立關聯。
- 使用者可以透過 AQL,在同一筆查詢中連結文件與圖形資料,不需額外整合層或 ETL 工具。
- 相比之下,其他圖形資料庫(如 Neo4j)在處理多模型時,常需外部系統輔助才能達到同樣彈性。
三、無模式架構(Schemaless)
- ArangoDB 支援「無需預先定義結構」的 Schemaless 架構。
- 這讓開發者能快速建立或修改資料結構,特別適合動態資料如知識圖譜與即時應用。
- 在業務需求快速變化的情況下,也大大減少資料遷移與轉換的時間成本。
四、全文搜尋內建支援:ArangoSearch
- ArangoDB 內建模組 ArangoSearch 提供強大全文搜尋能力。
- 它不是單純的 LIKE 或 CONTAINS 關鍵字比對,而是類似 ElasticSearch 的全文倒排索引引擎。
- 最大優勢是:不需要外部模組即可完成複雜搜尋需求,像是排序、打分、語意分析等都能搞定。
多模型的戰略優勢:
一、單一資料庫處理複合資料結構
- 現代應用系統往往需要處理多種資料型態,例如:
- 使用者資料是結構化的 JSON 文件。
- 商品與類別之間存在層級或圖狀關係。
- 權限控制或推薦系統需進行圖形遍歷。
- 在傳統架構中,這些資料可能會被分散存放在 MongoDB、Neo4j 與 PostgreSQL 等不同系統。這不僅加重了系統整合的負擔,也導致維運與資料一致性管理的困難。
- 使用 ArangoDB 的好處是:這三種資料型態可同時在同一個資料庫內部自然共存,且不需在系統層面進行額外整合。
二、查詢整合與語言一致性
ArangoDB 使用單一查詢語言 AQL(Arango Query Language),不論是:
- 搜尋 JSON 文件中的欄位值(類似 SQL 的 SELECT)
- 做圖形遍歷(如從某個節點開始找出關聯的使用者)
- 結合不同資料集合(類似 JOIN 操作)
都可以透過 AQL 一致地完成,省去在應用層拼裝多套查詢語法的麻煩。例如:
FOR user IN Users
FILTER user.age > 30
FOR friend IN 1..2 OUTBOUND user FriendEdges
RETURN {user: user.name, friend: friend.name}上述查詢同時涵蓋了 document 過濾(FILTER user.age > 30)與 graph traversal (FOR friend IN 1..2 OUTBOUND user FriendEdges)。
三、資料模型演進彈性
開發初期可能只需要簡單的文件結構(Document Model),但隨著需求演進,可能會逐漸引入:
- 圖形關係:例如使用者之間的追蹤關係、文章之間的引用。
- 跨集合的關聯邏輯:例如訂單關聯到使用者與商品。
- 使用 ArangoDB 可以逐步引入新的資料模型,而無需重構或轉移至其他資料庫系統,這在新創或快速變動的專案中特別有價值。
四、降低系統複雜度與成本
在單一資料庫引擎下整合多種模型,可大幅減少:
- 開發與維運成本(無需部署與監控多套資料庫)
- 資料同步與一致性處理(無需處理多來源資料一致問題)
- 效能瓶頸與資料搬移問題。
此外,ArangoDB 提供的原生分片(sharding)與分散式部署功能,也讓它能處理大規模資料與橫向擴展需求,無須依賴額外中介層。
五、跨模型的資料交互性
舉例來說,如果你儲存社群平台的使用者、貼文、留言、與追蹤關係:
- 使用者、貼文、留言可以是文件(Document)
- 追蹤與留言關係可以建成圖形(Graph)
- 貼文與留言的查詢結果又可以結合其他欄位做彙總、篩選等操作。
透過 AQL 查詢,這些資料可以在一次查詢中整合處理,無需資料層轉換,效能與維護都相對穩定。
❮ 多模型資料庫的優勢優勢 ❯
| 優勢 | 描述 | 戰略影響 |
|---|---|---|
| 簡化架構 | 將資料管理整合到單一系統,減少維護和整合 | 精簡 IT、降低營運開銷 |
| 效能提升 | 透過利用各資料模型優勢,最佳化資料儲存與檢索 | 更快的洞察力、提高效率 |
| 增強資料一致性 | 單一後端支援 ACID,確保跨模型資料完整性 | 風險緩解、提高資料可信度 |
| 降低營運複雜性 | 管理的資料庫技術減少,降低總體擁有成本 | 成本節約、資源重新分配 |
| 提高靈活性 | 適應多樣化資料結構;敏捷適應不斷變化的需求 | 業務敏捷性、快速市場回應 |
| 縮短開發時間 | 統一 API 和查詢語言加速開發週期 | 更快的產品上市、高效資源利用 |
ArangoDB 與 Neo4j:技術與效能的比較分析
在圖形資料庫領域,ArangoDB 和 Neo4j 都是領先的解決方案,但它們在架構和功能上存在顯著差異,這影響了它們在不同用例中的適用性。
資料模型與查詢語言:AQL 與 Cypher
一、資料模型
- Neo4j: 主要是一個單一模型的圖形資料庫,專門遵循屬性圖形模型。資料被結構化為節點和關係,並透過標籤和屬性提供更細緻的分類和屬性。這種專注使其在純圖形工作負載中表現出色。
- ArangoDB: 作為一個多模型資料庫,ArangoDB 獨特地將圖形、文件和鍵值模型整合到一個單一核心中。這種架構允許儲存多樣化的資料結構並同時查詢它們,為企業提供了極大的靈活性。
二、查詢語言
- Neo4j (Cypher): Cypher 是由 Neo4j 創建的聲明式圖形查詢語言,現在是 openCypher計畫的一部分。Cypher 使用直觀、視覺化的 ASCII 藝術語法來表達節點和關係的模式,使其易於學習和理解。它針對圖形遍歷和複雜圖形模式進行了最佳化,消除了對互連資料進行複雜 SQL 連接的需求。
- ArangoDB (AQL): ArangoDB 查詢語言 (AQL) 是一種聲明式語言,其目的與 SQL 相似,但專為多模型資料設計。儘管其語法與 SQL 不同,但對於具有 SQL 背景的人來說通常很容易學習。AQL 的主要優勢在於它能夠在單一查詢中結合不同的資料模型和功能,從而實現對圖形、文件和鍵值資料的統一查詢。
效能基準:圖形計算與載入效率
一、ArangoDB 與 Neo4j:效能基準測試的多重視角
在比較 ArangoDB 與 Neo4j 的效能表現時,不同來源的基準測試揭示出截然不同的結果,這凸顯出「測試環境與應用場景契合度」的重要性。
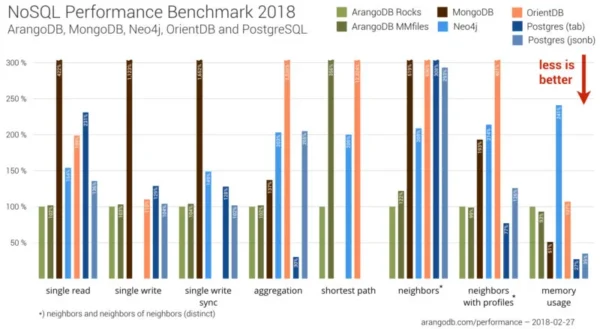
二、來自 ArangoDB 的官方基準測試(2024 年 12 月)
使用 Wiki-Talk 資料集,由 ArangoDB 官方贊助的測試顯示,ArangoDB 在多種圖形演算法中表現優於 Neo4j,效能提升介於 1.3 倍 ~ 8.5 倍。具體加速成果:
- PageRank:快 2.8 倍
- WCC(Weakly Connected Components):快 1.7 倍
- SCC(Strongly Connected Components):快 2.1 倍
- Label Propagation:快 8.5 倍
在圖形資料載入階段,載入速度提升達 100%。
效能優勢來源包括:
- 平行資料提取機制:支援單一與分散系統平行載入。
- 投影資料傳輸:僅提取需要的欄位,減少 I/O。
- 高效圖形分析引擎 GAE:以 Rust 寫成、採用最佳化記憶體結構。
三、來自 ResearchGate 的獨立研究(2025 年 2 月)
使用 ogbl_biokg 資料集,這份學術研究帶來不同觀點:
- 在「查詢互連資料」場景中,Neo4j 明顯快於 ArangoDB 與 MySQL。
- ArangoDB 在複雜查詢執行時間上是三者中最慢的。
- CPU 使用率與能耗:Neo4j 與 ArangoDB 相當,且都優於 MySQL。
- 記憶體效率:兩者皆優於傳統資料庫。
四、解讀測試差異的背後意義
這兩份測試結果的差異反映出:
效能高低 ≠ 絕對真理,而取決於應用場景、資料型態與架構設計權衡
Neo4j vs. ArangoDB
Neo4j 的專業化特點:
- 為圖形資料而生,針對圖形遍歷與演算法高度優化。
- 若工作負載是「靜態資料上的純圖形查詢」,Neo4j 往往是最快的。
ArangoDB 的多功能性定位:
- 優勢在於整合:同時處理圖形、文件、鍵值與全文資料,架構簡潔、開發一致性強。
- 在涉及大量資料載入、圖形分析前處理(如 ETL、血緣追蹤)場景中,表現優異。
五、給企業的決策建議:效能 ≠ 唯一考量
效能比較不是單純的快或慢問題,而是戰略選擇的反映:
| 選擇焦點 | 適合資料庫 | 原因 |
|---|---|---|
| 專業化圖形運算 | Neo4j | 純圖形優化、深層遍歷快 |
| 多元資料整合 + 彈性架構 | ArangoDB | 一站式處理多模型資料,降低整合負擔 |
六、選擇技術時,請避免僅根據某一方贊助的基準數據
更重要的是:依據實際工作負載進行 PoC 測試,確認資料規模、查詢特性與延遲需求是否契合該系統架構。例如:
- 如果你的詐欺偵測系統是即時載入 + 多跳關聯查詢 + AI 分析整合 → ArangoDB 較合適。
- 如果你只針對既有靜態圖資料做深層圖分析 → Neo4j 可望有更佳圖形查詢效能。
可擴展性、一致性與部署考量
一、可擴展性:
兩種資料庫都設計為可擴展。ArangoDB 支援對大型、高度互連資料集的橫向擴展,包括分片和複製。它既可以垂直擴展,也可以橫向擴展,以適應不斷增長的效能和儲存需求。
二、ACID 事務:
許多圖形資料庫,包括 ArangoDB,都為圖形操作提供 ACID 事務,這對於資料完整性至關重要。ArangoDB 在單一實例上提供強大的一致性,並在叢集模式下提供原子操作。其「OneShard」部署選項在分片領導者上提供 ACID 保證,建議用於大多數圖形用例和重連接查詢,同時透過同步複製確保彈性。
三、部署:
ArangoDB 提供靈活的部署選項,包括內部部署或作為雲端託管服務。
❮ ArangoDB 與 Neo4j:主要差異點 ❯
| 功能 | ArangoDB | Neo4j | 備註/情境 |
|---|---|---|---|
| 資料模型 | 多模型 (圖形、文件、鍵值、搜尋) | 屬性圖形 (單一模型) | ArangoDB 適用於多樣化資料類型整合,Neo4j 專注於純圖形 |
| 查詢語言 | AQL (類似 SQL,統一) | Cypher (視覺化,圖形最佳化) | AQL 跨模型查詢,Cypher 專為圖形模式設計 |
| 多模型支援 | 是 (核心優勢) | 否 (單一模型) | ArangoDB 簡化架構和資料一致性 |
| 主要用例焦點 | 多功能 (整合、多樣化資料) | 專業化 (純圖形分析) | ArangoDB 適合複雜企業資料環境,Neo4j 適合深度圖形分析 |
| 效能 (總體) | 強 (特別是 GAE 特定工作負載) | 快 (特別是某些研究中的互連資料查詢) | 效能基準因資料集和方法論而異 |
| 效能 (圖形載入) | 優越 (在某基準測試中具 100% 優勢) | 效率較低 (在某基準測試中) | ArangoDB 在其贊助的基準測試中顯示出載入優勢 |
| 效能 (圖形計算) | 優越 (在某基準測試中快 1.3 倍至 8 倍) | 較慢 (在某基準測試中) | ArangoDB 在其贊助的基準測試中顯示出計算優勢 |
| ACID 事務 | 是 (強一致性,原子性,OneShard) | 是 (圖形操作的 ACID) | 兩者皆提供 ACID,ArangoDB 的OneShard 針對圖形用例提供特定優勢 |
| 營運複雜性 | 降低 (單一後端) | 較高 (多語言持久化需求) | ArangoDB 透過整合降低管理負擔 |
ArangoDB 在金融服務業的應用:現代挑戰的解決方案
金融服務業正面臨前所未有的資料管理與分析挑戰,源自於資料規模的急遽增長、結構的複雜性,以及持續演變的監管要求。ArangoDB 憑藉其多模型架構與先進的圖形處理能力,提供一套統合且具前瞻性的資料平台,能有效應對金融領域的核心難題。
應對金融資料的複雜性:數量、真實性、血緣與監管合規
金融機構正努力應對資料爆炸式增長和複雜性帶來的多重挑戰,金融機構正面臨下列主要挑戰:
一、資料規模與一致性問題
資料量呈指數增長,單一銀行每日處理數百萬筆交易,涵蓋貸款、存款、資產管理與風險控管等領域,產出數 TB 的關鍵資料。由於資料來自異質系統,若處理流程或演算法不一致,可能導致同一客戶的信用風險在不同系統中產生矛盾數值,增加手動調整與營運風險。
二、資料血緣與可追溯性不足
許多金融機構缺乏有效的資料血緣管理,難以追蹤資料從來源擷取、轉換至最終報表的全流程。這不僅對於合規申報形成障礙,也使問題追蹤流程冗長繁瑣,無法快速定位資料異常的根本原因。這正是 BCBS 239 等監管準則強調資料可追溯性與透明化的緣由。
三、資料品質與 AI 可解釋性挑戰
隨著 AI 與機器學習模型廣泛應用於信用評估、風險計量及詐欺偵測,資料品質與來源透明性成為合規焦點。模型所用資料來自內部與外部來源(部分為非結構化資料),易受偏誤影響,進而影響模型可信度與監管審核結果。
四、遺留系統與現代化障礙
傳統核心系統往往為單一功能設計,不具備靈活的資料整合與查詢能力。當面臨監管規範更新或需整合 AI/ML 應用時,往往需進行大量程式改動與 ETL 處理,造成高昂的維運成本與長週期延遲。
五、詐欺手法日益複雜
監管要求同步升級, 詐欺行為已由個體轉向有組織的犯罪團夥,利用多層交易結構與匿名通訊管道掩蓋其軌跡。同時,金融機構亦須在平衡用戶體驗、跨境交易、GDPR/CCPA 等法規與資安合規之間取得平衡。
ArangoDB 提供的關鍵解決方案:
在現代詐欺手法日益複雜的情況下,單靠單筆交易比對已無法揭示潛在風險。ArangoDB 提供一套具備圖形關聯與即時查詢能力的解決方案,能更有效追蹤異常行為與詐騙網路。
一、解決方式:圖形資料驅動的行為分析
- 整合資料來源:將歷史交易、裝置登入紀錄、客戶資料結合起來。
- 運用圖形模型進行查詢:透過節點(人/裝置)與邊(交易/登入行為)之間的多層關聯,識別潛在詐騙群體。
- 查詢方式範例:透過 ArangoDB 的 AQL,可以撰寫如「從使用者 A 出發,找出 2~4 跳內所有與其有轉帳關聯的人與帳戶」這類查詢。
二、效能特性:毫秒級的圖形關聯查詢
- 支援多跳(multi-hop)關係查詢,速度可達毫秒級反應。
- 例如:追蹤資金從使用者 A 經過 3 層轉帳流向使用者 B,可在數百毫秒內得出結果。
- AQL 的語法設計簡潔,讓這類查詢易寫、好維護、不易錯。
三、與傳統系統比較:彈性差異顯著
| 技術 | 做多跳關聯查詢 | 維護難度 | 查詢效能 |
|---|---|---|---|
| 關聯式資料庫 (SQL) | 需多表 JOIN + 遞迴 | 高 | 中~低 (複雜查詢時急遽下降) |
| ArangoDB (AQL) | 原生支援圖形遍歷 | 低 | 高 (尤其在大圖中仍穩定) |
這讓 ArangoDB 特別適合用於金融詐欺偵測、組織犯罪追蹤、關聯洗錢分析等需求。
實際應用:金融業案例研究與成功案例
-
Refinitiv - Refinitiv 官網
Refinitiv 作為全球金融資訊供應商,使用 ArangoDB 構建高效的圖形關係平台,以優化資訊推送與監管回應速度。“ArangoDB 是一個真正的開源項目,另一個重要優勢是其微服務框架Foxx…”
-
Tazama - Tazama 官網
舊金山,2024年10月23日電 /美通社/ -- Linux 基金會旗下專案 Tazama 與 ArangoDB 攜手合作,為數位支付系統提供即時詐欺偵測功能,開創性地在全球範圍內打擊金融詐欺。此次合作將 Tazama 創新的交易監控方法與 ArangoDB 市場領先的圖形資料庫技術完美結合。
引述來源
“Detect fraud before it happens.” - 需要更多的案例,請與 ArangoDB 連絡
❮ ArangoDB 解決的金融業挑戰 ❯
| 金融業挑戰 | ArangoDB 能力 | 影響/效益 |
|---|---|---|
| 資料量、真實性與規模 | 多模型資料擷取與統一查詢 | 有效處理多樣化資料;降低資料衝突 |
| 不當資料血緣 | 圖形建模用於血緣與知識圖譜 | 清晰的資料可追溯性與可審計性;滿足監管要求 (如 BCBS 239) |
| 資料品質不足 | 多模型整合與模式彈性 | 提高 AI/ML 資料完整性;支援資料來源文件 |
| 遺留技術限制 | 多模型資料擷取與統一平台 | 無縫整合與現代化;避免複雜 ETL |
| 不斷演變的詐欺技術 | 高效能圖形分析與 AQL 複雜模式 | 即時詐欺偵測與預防;識別複雜詐欺團夥 |
| 監管合規 | 知識圖譜與 ACID 事務 | 強大的風險評估與合規性;簡化監管報告 |
| 資料隱私 | 安全資料管理與 ACID 事務 | 遵守隱私法規 (如 GDPR);確保資料安全 |
總結
ArangoDB 是金融業數位轉型的強大助力,結合圖形智慧與資料整合力,為詐欺防堵、合規查詢與客製服務提供一站式解決方案。隨著圖神經網絡(GNN)與向量搜尋的崛起,圖形資料庫將在金融 AI 領域發揮更大潛力,ArangoDB 的多模型架構可望成為未來關鍵技術基石。